
- MMM Factory - Industrialisation du marketing mix modeling
- Synomia by Converteo
Retour
Votre secteur
- Cas client
- Evènement
- Livre blanc
- Podcast
- Webinar
Retour
Ressources
Grâce à l'IA sémantique, nous transformons tous les signaux spontanés disponibles sur le web et les réseaux sociaux en intelligence (études, baromètres) au service de vos décisions, de vos actions.

Synomia by Converteo, c'est une technologie propriétaire d’analyse sémantique par l’IA prolongée par une activité de conseil aux directions des entreprises.
Nous récupérons une donnée spontanée et massive, partagée librement en ligne par les consommateurs, les média, les marques, les différentes parties prenantes sans questionnaire et sans a priori.
Nous étudions cette donnée, en mobilisant plusieurs traitements d'IA sémantique pour la structurer, la qualifier, la hiérarchiser et lui donner du sens afin de répondre à vos enjeux.
Nos livrables : diagnostics, audit et études, baromètres récurrents sur une perception de marque, un positionnement RSE, un produit, une innovation servicielle, une thématique, un événement, une personnalité...
Nos datavisualisations : cartographie, persona, customer journey, benchmark, communautés digitales...
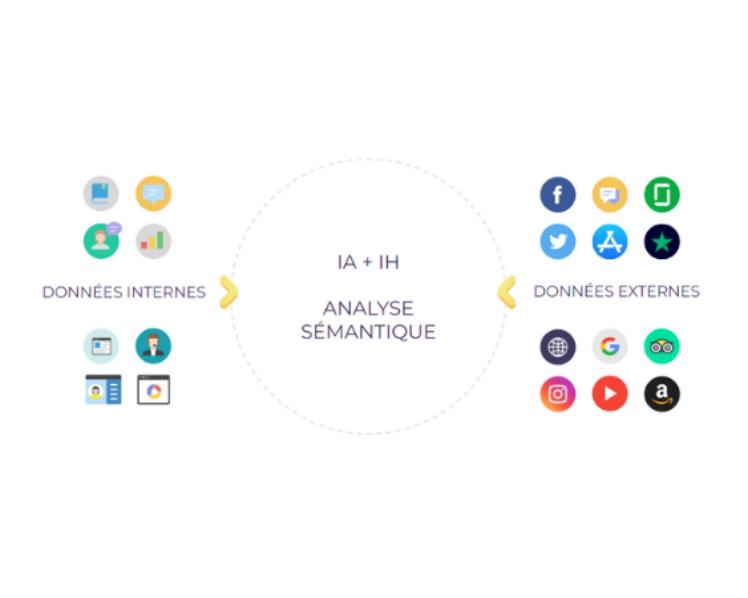
DONNÉES INTERNES
Nous révélons des insights internes en nous connectant aux systèmes d'information de votre entreprise :
- Études & sondages,
- Conversations par chat,
- Informations du CRM & DMP,
- Données provenant du service client,
- Données collectées par l'outil d'analyse web Google Analytics, Piano ou autre.
- Documents digitalisés, etc
DONNÉES EXTERNES
Notre technologie se déploie sur des territoires digitaux où les volumes de conversations sont inaccessibles sans IA :
- Réseaux sociaux : Facebook et Twitter
- Forums,
- Sites d'avis clients,
- Avis des AppStores (Apple Store, Google Play Store...),
- Sites concurrents,
- Markeplaces
- Sites média...
Détection de tendances, drivers, comportements, signaux faibles et dynamiques pour nourrir les stratégies Marketing et innovation.
Détection et qualification de cibles de conquête Enrichissement de la connaissance client (ou cibles RH)
Amélioration de l’efficacité des stratégies de communication et de contenu éditorial ou marketing.


Cartographie des parties prenantes d’un écosystème digital, permettant de positionner une Marque et d’identifier les opportunités marketing et communication.
Renfort de position de Marque versus concurrence, sur un parcours d’achat ou un parcours de décision.
Construction d’indicateurs adhoc (observatoire, baromètre) permettant le pilotage d’activité














